
Last Friday 17th of December, Wenceslao Arroyo-Machado and Nicolas Robinson-Garcia presented their work in progress Big Data and the birth of a Science of the Humanities at the 1st International Conference on Humanities and Big Data in Ibero-America organized by IberLab UGR which took place on 16-17th December, 2021 in Granada. This presentation shows some preliminary results exploring Dialnet and ORCID as potential sources to track academic activity in the fields of the Humanities. For this, we first revise the main limitations scientometric studies have identified when studying Humanities and humanists’ research performance. Second, we discuss how the increase in size and variety of data sources plus the use of machine learning techniques can help overcome such limitations. We present two case studies using DIALNET and ORCID. We end up by discussing a potential road map for better understanding scholarly communication patterns and the production of knowledge in the Humanities.
DIALNET and ORCID: A win-win combination
DIALNET is considered one of the largest repositories of Spanish-speaking literature in the fields of the Social Sciences and the Humanities. It also happens to be a collaborating partner with the COMPARE project by granting access to their manually curated author profiles for all researchers publishing in any field within the Humanities. This provided us with a golden set of Spanish and Latin American humanists and their academic works. DIALNET includes not only journal publications, but also monographs, chapters and conference proceedings.
ORCID is an open registry of academics in which any researcher can create a profile and include their academic information, including educational background, job placement, funding acquisition and academic outputs. Regarding the later, it includes a large set of document types (over 40 different types of works). Researchers can also add keywords defining their research interests. Despite the rich possibilities it offers, as a user-driven tool, the quality of its data relies on its uptake, with many profiles incomplete and with missing data, and no quality control. In our first case study we combined data from both sources, aiming at identifying as many humanists as possible, as well as a complete collection of their works by combining information from both data sources plus filtering in ORCID by author keywords and affiliation departments (i.e., searching for humanities related department).
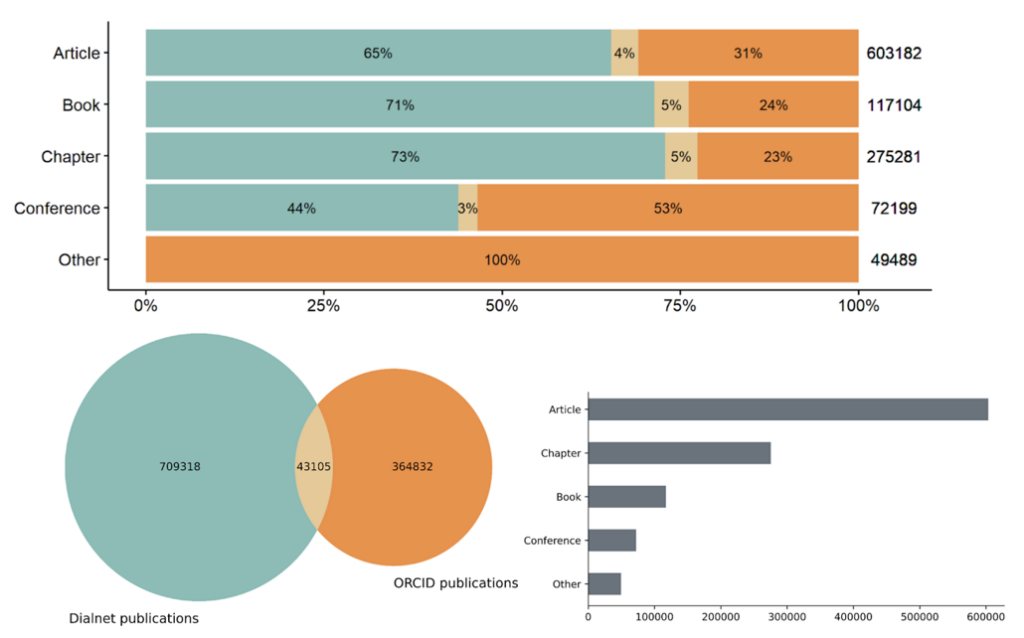
Publication patterns of humanists
Following the seminal work of Diana Hicks on The four literatures of social sciences, we aimed at profiling humanists based on the type of outputs they produce. Our argument was that not only their publication venues are diverse, but also that the profile of humanists between and within their different fields is also quite diverse. By using Archetypal Analysis, a promising technique for profiling individuals based on multivariate data, we were able to discern different archetypes of humanists and also analyse how is our population of humanists distributed in terms of similarity to each of these archetypes.
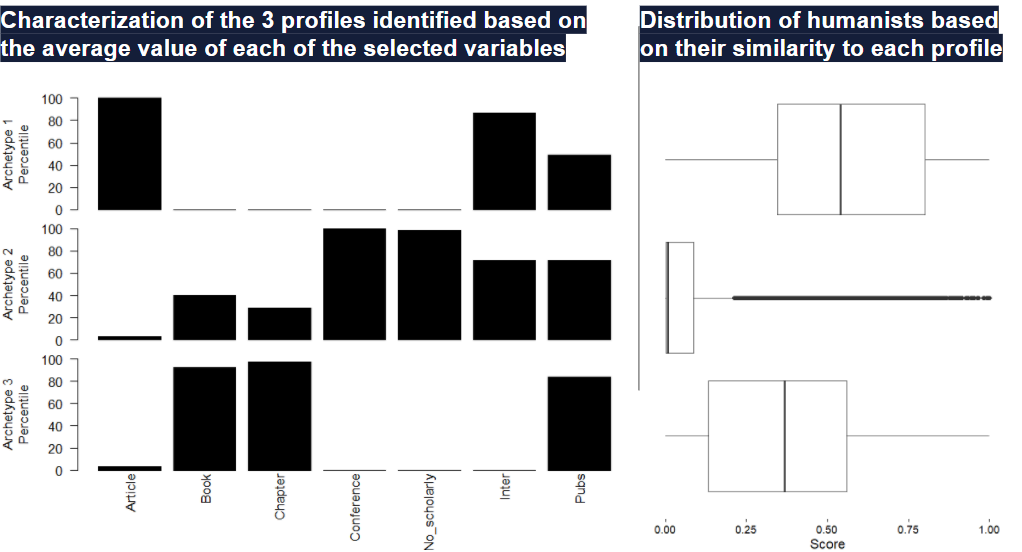
The findings of this study will be published in a forthcoming book titled Humanities and Big Data in Ibero-America to be published by De Gruyter, and edited by Ana Gallego-Cuiñas and Daniel Torres-Salinas, member of the COMPARE team.
Reference
Arroyo-Machado, W., Robinson-Garcia, N. Big Data and the birth of a Science of Humanities. 1st International Conference on Humanities and Big Data in Ibero-America, Granada, December, 16-17, 2021